// dijstra while(pq.size() > 0) { auto node = pq.top(); pq.pop(); int u = node.second; int dis = node.first;
// for disRes[u], every relax will push a new pair, so we need // to pass all old relaxed value /** * * eg: [[2,3,4],[1,3,9],[0,2,4],[0,1,1]] * 对于上图的dijstra的距离表的松弛过程为: 0 2 2147483647 2147483647 0 2 5 2147483647 0 2 5 12 // 这里,第一次松弛来自节点1, 0 2 5 10 // 第二次来自节点2,那么这两个松弛结果都会记录在pq里面,为了让后面 // pq遍历到 0到3距离为12的时候能pass掉,我么你需要将12和 10(存于距离中)做比较, // 就可以直到12是第一次松弛的结果,10才是最终松弛的结果,否则如果还有其他节点, // 那么12会在10松弛完其他节点接着松弛,那就错了 // 于是这个continue是必要的 */ if(disRes[u] < dis) { continue; } visited[u] = true; disRes[u] = dis; res += (disRes[u] <= maxMoves);
// relax nodes by u for(auto& neighbor : g[u]) { int v = neighbor.first; int w = neighbor.second; // v has been proceed! if(!visited[v] && disRes[v] > disRes[u] + g[u][v]) { disRes[v] = disRes[u] + g[u][v]; pq.push({disRes[v], v}); // print(disRes); } } };
// dijstra while(pq.size() > 0) { auto node = pq.top(); pq.pop(); int u = node.second; int dis = node.first;
// for disRes[u], every relax will push a new pair, so we need // to pass all old relaxed value if(disRes[u] < dis) { continue; } visited[u] = true; disRes[u] = dis; res += (disRes[u] <= maxMoves);
// relax nodes by u for(auto& neighbor : g[u]) { int v = neighbor.first; int w = neighbor.second; // v has been proceed! if(!visited[v] && disRes[v] > disRes[u] + g[u][v]) { disRes[v] = disRes[u] + g[u][v]; pq.push({disRes[v], v}); print(disRes); } } }
// count sub nodes for(auto& e : edges) { int u = e[0]; int v = e[1]; int w = e[2]; int curSubNodes = 0; if(visited[u]) { curSubNodes += max(maxMoves - disRes[u], 0); } if(visited[v]) { curSubNodes += max(maxMoves - disRes[v], 0); } curSubNodes = min(curSubNodes, w); // cout << "curSub/edge: " << curSubNodes << " " << "e: " << u << "->" << v << endl; res += curSubNodes; }
voidbinSearchAdjTwoAndUpdate(int tar, int r, int goal, vector<int>& leftSet, int& minAbs){ auto it1 = lower_bound(leftSet.begin(), leftSet.end(), tar); if(it1 == leftSet.end()) { int l = *(it1 - 1); minAbs = min(abs(l + r - goal), minAbs); } elseif(it1 == leftSet.begin()) { int l = *(it1); minAbs = min(abs(l + r - goal), minAbs); } else { int l1 = *it1; int l2 = *(it1 - 1); minAbs = min(abs(l1 + r - goal), minAbs); minAbs = min(abs(l2 + r - goal), minAbs); } }
// 注意题目说的是子序列,而不是子数组 // 考虑复杂度:如果枚举所有子序列,2^40,那么将数组分成两半去枚举:2^20 * 2 intminAbsDifference(vector<int>& nums, int goal){ int n = nums.size(); int mid = n >> 1; auto leftSet = makeSubSeqSum(vector<int>{nums.begin(), nums.begin() + mid}); auto rightSet = makeSubSeqSum(vector<int>{nums.begin() + mid, nums.end()});
classSolution { public: longlonggetLCM(longlong x, longlong y){ return x * y / getGCD(x, y); } longlonggetGCD(longlong x, longlong y){ longlong l = min(x, y); longlong g = max(x, y); longlong mod = g % l; while(mod != 0) { g = l; l = mod; mod = g % l; } return l; } constexprstaticint MOD = 1'000'000'007;
intnthMagicalNumber(int n, int a, int b){ longlong lcm = getLCM(a, b); auto getMagicRank = [&](longlong x) { return x / a + x / b - x / lcm; }; longlong st = 0; longlong ed = 1e15;
classSolution { public: intgetKthElement(vector<int>& nums1, vector<int>& nums2, int k){ // cout <<"------------" << endl; int idx1 = k / 2 - 1; int m = nums1.size(); int n = nums2.size(); int st1 = 0; int st2 = 0;
// -------------------------------- 算法本身 For each pixel i sum_of_weights = sum_of_weighted_values = 0.0 For each pixel j around i Calculate the weight w_ij = G(|i - j|, sigma) sum_of_weighted_values += w_ij * C^{input}[j] sum_of_weights += w_ij C^{output}[I] = sum_of_weighted_values / sum_of_weights
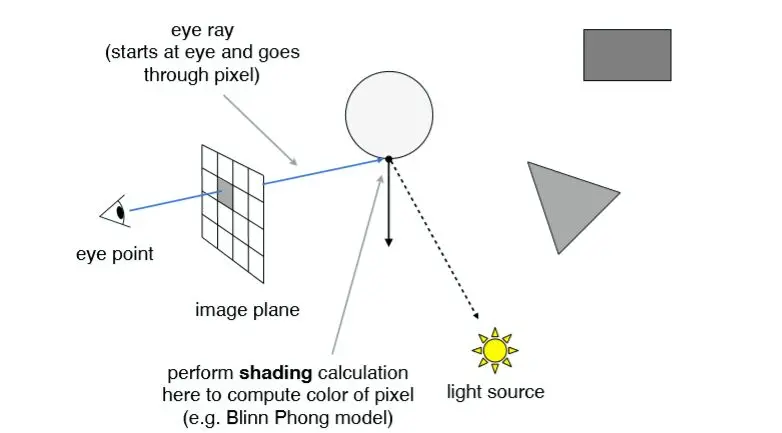
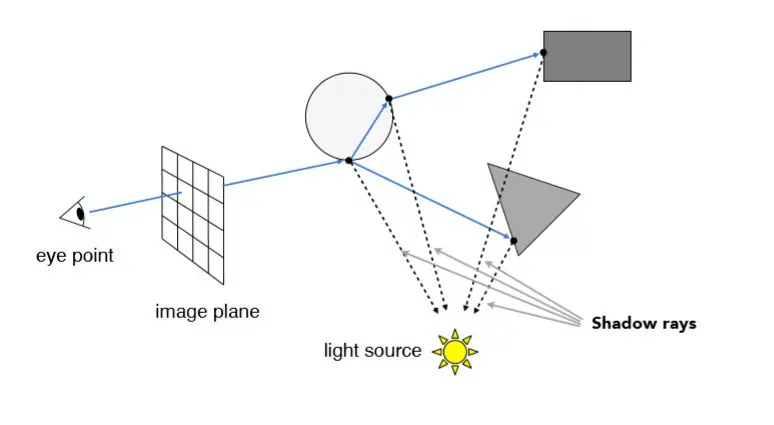
// Use this variable as the eye position to start your rays. Vector3f eye_pos(0); int m = 0; for (int j = 0; j < scene.height; ++j) { for (int i = 0; i < scene.width; ++i) { // generate primary ray direction float x; float y; // TODO: Find the x and y positions of the current pixel to get the direction // vector that passes through it. // Also, don't forget to multiply both of them with the variable *scale*, and // x (horizontal) variable with the *imageAspectRatio* // To NDC space x = (float)i / scene.width - 0.5; y = (float)(scene.height - j) / scene.height - 0.5; // To world space x *= scale * imageAspectRatio; y *= scale;
Vector3f dir = Vector3f(x, y, -1); // Don't forget to normalize this direction! dir = normalize(dir); framebuffer[m++] = castRay(eye_pos, dir, scene, 0); } UpdateProgress(j / (float)scene.height); }
int depth = 1; while(!curLevel.empty()) { int curSize = curLevel.size(); // pop all curLevel and do next level while(curSize-- > 0) { // 最关键的,一定不要直接写成curLevel.size,因为curLevel会放后面的节点的呜呜呜 auto board = curLevel.front(); curLevel.pop();
auto coord = getPos(board); int x = coord.first; int y = coord.second; for(int mv = 0; mv < 4; ++mv) { int nextX = x + dx[mv]; int nextY = y + dy[mv]; if(0 <= nextX && nextX < 2 && 0 <= nextY && nextY < 3) { swap(board[nextX][nextY], board[x][y]); // cout << "trying : " << x << ", " << y << " to " << nextX << ", " << nextY << " withd d = " << depth <<endl; // print(board); int intBoard = toInt(board);
int depth = 1; while(!curLevel.empty()) { int curSize = curLevel.size(); // pop all curLevel and do next level while(curSize-- > 0) { auto board = curLevel.front(); curLevel.pop();
auto coord = getPos(board); int x = coord.first; int y = coord.second; for(int mv = 0; mv < 4; ++mv) { int nextX = x + dx[mv]; int nextY = y + dy[mv]; if(0 <= nextX && nextX < 2 && 0 <= nextY && nextY < 3) { swap(board[nextX][nextY], board[x][y]); // cout << "trying : " << x << ", " << y << " to " << nextX << ", " << nextY << " withd d = " << depth <<endl; // print(board); int intBoard = toInt(board);
classSolution { public: int m; int n; int dx[4] = {1, 0, -1, 0}; int dy[4] = {0, -1, 0, 1}; int dirs[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}}; intcutOffTree(vector<vector<int>>& forest){ // get all trees m = forest.size(); n = forest[0].size();
auto cmp = [](const pair<pair<int, int>, int>& a, const pair<pair<int, int>, int>& b) { return a.second > b.second; }; priority_queue<pair<pair<int, int>, int>, vector<pair<pair<int, int>, int>>, decltype(cmp)>trees (cmp);
for(int i = 0; i < m; ++i) { for(int j = 0; j < n; ++j) { if(forest[i][j] > 1) { trees.push({{i, j}, forest[i][j]}); } } }
int curX = 0, curY = 0; int tarX = -1, tarY = -1; int res = 0; while(!trees.empty()) { auto tree = trees.top(); trees.pop();
intbfs(vector<vector<int>>& forest, int sx, int sy, int tx, int ty){ if (sx == tx && sy == ty) { return0; }
int row = forest.size(); int col = forest[0].size(); int step = 0; queue<pair<int, int>> qu; vector<vector<bool>> visited(row, vector<bool>(col, false)); qu.emplace(sx, sy); visited[sx][sy] = true; while (!qu.empty()) { step++; int sz = qu.size(); for (int i = 0; i < sz; ++i) { auto [cx, cy] = qu.front(); qu.pop(); for (int j = 0; j < 4; ++j) { int nx = cx + dirs[j][0]; int ny = cy + dirs[j][1]; if (nx >= 0 && nx < row && ny >= 0 && ny < col) { if (!visited[nx][ny] && forest[nx][ny] > 0) { if (nx == tx && ny == ty) { return step; } qu.emplace(nx, ny); visited[nx][ny] = true; } } } } } return-1; }
// using bfs from <curX, curY> to <tarX, tarY>, the depth of bfs should be the distance booltryWalk(vector<vector<int>>& forest, int curX, int curY, int tarX, int tarY, int& res){ // bfs queue<pair<int, int>> curLevel; vector<vector<int>> vis(m, vector<int>(n, false)); curLevel.push({curX, curY}); vis[curX][curY] = true;
int depth = 0; while(!curLevel.empty()) { // queue<pair<int, int>> nextLevel;
// while(!curLevel.empty()) { int curLevelSize = curLevel.size(); while(curLevelSize-- > 0) { auto curNode = curLevel.front();
curLevel.pop(); if(curNode == pair<int, int>{tarX, tarY}) { // update res res += depth; returntrue; } for(int mv = 0; mv < 4; ++mv) { int nextX = curNode.first + dx[mv]; int nextY = curNode.second + dy[mv];
while(!curLevel.empty()) { int curSize = curLevel.size(); while(curSize-- > 0) { auto curNode = curLevel.front(); int curDis = dis[curNode]; int x = curNode.first.first; int y = curNode.first.second; int curKey = curNode.second;
vec3 T = normalize(vec3(model * vec4(tangent, 0.0))); vec3 N = normalize(vec3(model * vec4(normal, 0.0))); // re-orthogonalize T with respect to N T = normalize(T - dot(T, N) * N); // then retrieve perpendicular vector B with the cross product of T and N vec3 B = cross(T, N);
// get texture coordinates before collision (reverse operations) vec2 prevTexCoords = currentTexCoords + deltaTexCoords;
// get depth after and before collision for linear interpolation float afterDepth = currentDepthMapValue - currentLayerDepth; float beforeDepth = texture(depthMap, prevTexCoords).r - currentLayerDepth + layerDepth;
// ----------------------------------- phase1 gbuffer获取纹理,法向,反射率给ssao shader #version 330 core layout (location = 0) out vec3 gPosition; layout (location = 1) out vec3 gNormal; layout (location = 2) out vec3 gAlbedo;
in vec2 TexCoords; in vec3 FragPos; in vec3 Normal;
voidmain() { // store the fragment position vector in the first gbuffer texture gPosition = FragPos; // also store the per-fragment normals into the gbuffer gNormal = normalize(Normal); // and the diffuse per-fragment color gAlbedo.rgb = vec3(0.95); }
// parameters (you'd probably want to use them as uniforms to more easily tweak the effect) int kernelSize = 64; // 减小然后去掉模糊,我们看一下ssao带来的波纹 float radius = 0.5; float bias = 0.025;
// 屏幕的平铺噪声纹理会根据屏幕分辨率除以噪声大小的值来决定 // tile noise texture over screen based on screen dimensions divided by noise size const vec2 noiseScale = vec2(800.0/4.0, 600.0/4.0);
uniform mat4 projection;
voidmain() { // get input for SSAO algorithm vec3 fragPos = texture(gPosition, TexCoords).xyz; vec3 normal = normalize(texture(gNormal, TexCoords).rgb); vec3 randomVec = normalize(texture(texNoise, TexCoords * noiseScale).xyz); // create TBN change-of-basis matrix: from tangent-space to view-space // 由于对每个表面法线方向生成采样核心非常困难,也不合实际,我们将在切线空间(Tangent Space)内生成采样核心,法向量将指向正z方向。 vec3 tangent = normalize(randomVec - normal * dot(randomVec, normal)); vec3 bitangent = cross(normal, tangent); mat3 TBN = mat3(tangent, bitangent, normal); // iterate over the sample kernel and calculate occlusion factor float occlusion = 0.0; for(int i = 0; i < kernelSize; ++i) { // get sample position vec3 samplePos = TBN * samples[i]; // from tangent to view-space samplePos = fragPos + samplePos * radius; // project sample position (to sample texture) (to get position on screen/texture) vec4 offset = vec4(samplePos, 1.0); offset = projection * offset; // from view to clip-space offset.xyz /= offset.w; // perspective divide offset.xyz = offset.xyz * 0.5 + 0.5; // transform to range 0.0 - 1.0 // get sample depth float sampleDepth = texture(gPosition, offset.xy).z; // get depth value of kernel sample // 。当检测一个靠近表面边缘的片段时,它将会考虑测试表面之下的表面的深度值;这些值将会(不正确地)影响遮蔽因子。 // range check & accumulate, 在这里根据它非常光滑地在第一和第二个参数范围内插值了第三个参数。如果深度差因此最终取值在radius之间, // 它们的值将会光滑地根据下面这个曲线插值在0.0和1.0之间 float rangeCheck = smoothstep(0.0, 1.0, radius / abs(fragPos.z - sampleDepth)); occlusion += (sampleDepth >= samplePos.z + bias ? 1.0 : 0.0) * rangeCheck; } occlusion = 1.0 - (occlusion / kernelSize); FragColor = occlusion; }
voidmain() { // 对于三个顶点,都去做这个 GenerateLine(0); // first vertex normal GenerateLine(1); // second vertex normal GenerateLine(2); // third vertex normal }
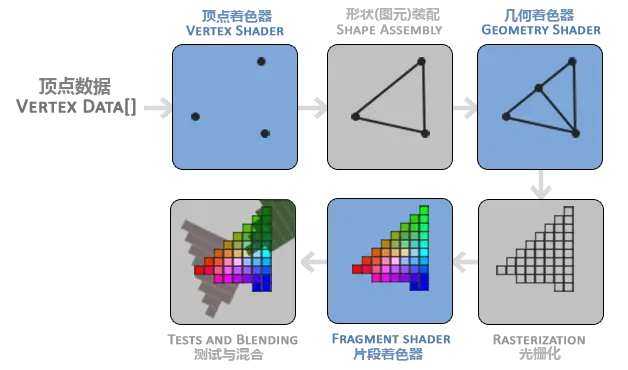
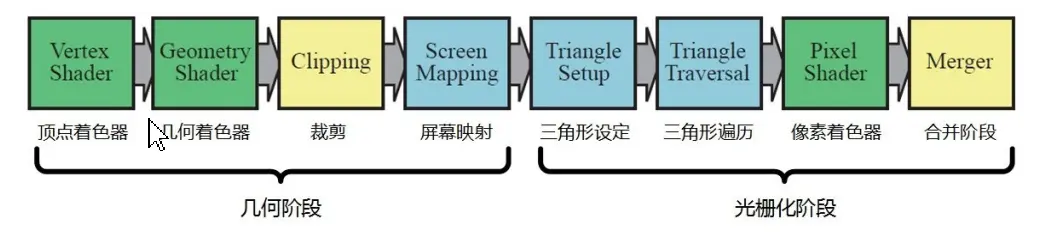
1 融合阶段:是将像素着色器中生成的各个片段的深度和颜色与帧缓冲结合在一起的地方。这个阶段也就是进行模板缓冲(Stencil-Buffer)和 Z 缓冲(Z-buffer)操作的地方。最常用于透明处理(Transparency)和合成操作(Compositing)的颜色混合(Color Blending)操作也是在这个阶段进行的。一下
// ambient *= attenuation; // remove attenuation from ambient, as otherwise at large distances the light would be darker inside than outside the spotlight due the ambient term in the else branche diffuse *= attenuation; specular *= attenuation; vec3 result = ambient + diffuse + specular; FragColor = vec4(result, 1.0); } else// 聚光灯外面 { // else, use ambient light so scene isn't completely dark outside the spotlight. FragColor = vec4(light.ambient * texture(material.diffuse, TexCoords).rgb, 1.0); } }
这里简单举个例子: 在text = abcccab中查找tar = ab出现次数,那么构造串: ab#abcccab,然后计算前缀函数: a b # a b c c c a b [0,0,0,1,2,0,0,0,1,2] = pi, 为前缀函数的结果,找出i>tar.size()且pi[i] == n的i的集合,每一个i - 2*tar.size()就是tar出现在text中的下标
classSolution { public: string shortestPalindrome(string s){ // prefix function && kmp: https://oi-wiki.org/string/kmp/#_10 int len = s.size(); string rs = s; reverse(rs.begin(), rs.end());
string all = s + "#" + rs; vector<int> pi(all.size(), 0); // see: our target is to find the "b c c b",so we use kmp // s = b c c b a e // rs = e a b c c b // all = b c c b a e # e a b c c b // 求解pi[i] for(int i = 1; i < all.size(); ++i) { // i - 1的前缀函数的值,有s[0:j] == s[i - j : i - 1] int j = pi[i - 1]; // 当s[i] != s[j],说明s[i]这个字符无法成为后缀的最后一个字符,此时pi[i] = 0,于是得一直找到下一个j,直到j = 0,或者s[i] == s[j] while(j > 0 && all[i] != all[j]) { j = pi[j - 1]; }
int x; // x是⼀个变量的名字,所以decltype(x) 是int。但是如果⽤⼀个小括号包覆这个名字,⽐如这样(x), // 就会产⽣⼀个⽐名字更复杂的表达式。对于名字来说,x是⼀个左值,C++11定义了表达式(x) 则是⼀个左值。因此decltype((x)) 是int&
//decltype(x)是int,所以f1返回int decltype(auto) f1(){ int x = 0; ... return x; } //decltype((x))是int&,所以f2返回int& decltype(auto) f2(){ int x =0l; return (x); }
classWidget { public: Widget(int i, bool b); // 同上 Widget(int i, double d); // 同上 Widget(std::initializer_list<longdouble> il); //新添加的 … }; Widget w1(10, true); // calls first ctor Widget w2{10, true}; // uses braces, but now calls std::initializer_list ctor (10 and true convert to long double) Widget w3(10, 5.0); // uses parens and, as before, calls second ctor Widget w4{10, 5.0}; // uses braces, but now calls std::initializer_list ctor, (10 and 5.0 convert to long double) Widget w5(w4); // 使⽤小括号,调⽤拷⻉构造函数 Widget w6{w4}; // 使⽤花括号,调⽤std::initializer_list构造函数 Widget w7(std::move(w4)); // 使⽤小括号,调⽤移动构造函数 Widget w8{std::move(w4)}; // 使⽤花括号,调⽤std::initializer_list构造函数
classWidget { public: Widget(int i, bool b); Widget(int i, double d); Widget(std::initializer_list<bool> il); // element type is now bool … // no implicit conversion funcs }; Widget w{10, 5.0}; //错误!要求变窄转换
// 优点1: 限域枚举(scoped enum),它不会导致枚举名泄漏 // 非限域枚举 enumColor { black, white, red }; // black, white, red 和 // Color⼀样都在相同作⽤域 auto white = false; // 错误! white早已在这个作⽤ // 域中存在
// 限域枚举 enum classColor { black, white, red }; // black, white, red // 限制在Color域内 auto white = false; // 没问题,同样域内没有这个名字 Color c = white; //错误,这个域中没有white Color c = Color::white; // 没问题 auto c = Color::white; // 也没问题(也符合条款5的建议)
// 优点2:在不存在任何隐式转换可以将限域枚举中的枚举名转化为任何其他类型,也就是拒绝隐式转换 enumColor { black, white, red }; // 未限域枚举 std::vector<std::size_t> // func返回x的质因⼦ primeFactors(std::size_t x); Color c = red; … if (c < 14.5) { // Color与double⽐较 auto factors = // 计算⼀个Color的质因⼦(!) primeFactors(c); … }
enum classColor { black, white, red }; // Color现在是限域枚举 Color c = Color::red; // 和之前⼀样,只是 多了⼀个域修饰符 … if (c < 14.5) { // 错误!不能⽐较Color和double auto factors = // 错误! 不能向参数为std::size_t的函数 primeFactors(c); // 传递Color参数 … }
// 若真的非常想,需要用类型转化如下: if (static_cast<double>(c) < 14.5) { // 奇怪的代码,但是有效 auto factors = // suspect, but primeFactors (static_cast<std::size_t>(c)); // 能通过编译 … }
// Rule of Three规则。这个规则告诉我们如果你声明了拷⻉构造函数,拷⻉赋值运算符, 或者析构函数三者之⼀,你应该也声明其余两个 // Rule of Three规则背后的解释依然有效,再加上对声明拷⻉操作阻⽌移动操作隐式⽣成的观察,使得C++11不会为那些有⽤⼾定义的析构函数的类⽣成移动操作。
auto spw = //spw创建之后,指向的Widget的 std::make_shared<Widget>(); //引用计数(ref count,RC)为1。 //std::make_shared的信息参见条款21 … std::weak_ptr<Widget> wpw(spw); //wpw指向与spw所指相同的Widget。RC仍为1 … spw = nullptr; //RC变为0,Widget被销毁。 //wpw现在悬空 if (wpw.expired()) … // if wpw doesn't point to an object
// 从weak_ptr创建shared_ptr std::shared_ptr<Widget> spw1 = wpw.lock(); // if wpw's expired, spw1 is null auto spw2 = wpw.lock(); // same as above, but uses auto std::shared_ptr<Widget> spw3(wpw); // if wpw's expired, throw std::bad_weak_ptr
// 在上⾯的 f({1,2,3}) 例⼦中,问题在于,如标准所⾔,将括号初始化器传递给未声明为 std::initializer_list 的函数模板参数,该标准规定为“⾮推导上下⽂”。简单来讲,这意味着编译器 在对fwd的调⽤中推导表达式 {1,2,3} 的类型,因为fwd的参数没有声明为 std::initializer_list 。 对于fwd参数的推导类型被阻⽌,编译器只能拒绝该调⽤。 // 有趣的是,Item2 说明了使⽤braced initializer的auto的变量初始化的类型推导是成功的。这种变量被 视为 std::initializer_list 对象,在转发函数应推导为 std::initializer_list 类型的情况,这 提供了⼀种简单的解决⽅法----使⽤auto声明⼀个局部变量,然后将局部变量转发: auto il = {1,2,3}; // il's type deduced to be std::initializer_list<int> fwd(il); // fine, perfect-forwards il to f
// 软件线程是有限的资源。如果开发者试图创建⼤于系统⽀持的硬件线程数量,会抛出 std::system_error 异常。即使你编写了不抛出异常的代码,这仍然会发⽣,⽐如下⾯的代码,即使 doAsyncWork 是 noexcept intdoAsyncWork()noexcept; // see Item 14 for noexcept // 这段代码仍然会抛出异常。 std::thread t(doAsyncWork); // throw if no more threads are available
// 有趣的是, std::async 的默认launch policy是以上两种都不是。相反,是求或在⼀起的。下⾯的两种 调⽤含义相同 auto fut1 = std::async(f); // run f using default launch policy auto fut2 = std::async(std::launch::async | std::launch::deferred, f); // run f either async or defered // 因此默认策略允许f异步或者同步执⾏。如同Item 35中指出,这种灵活性允许 std::async 和标准库的 线程管理组件(负责线程的创建或销毁)避免超载。这就是使⽤ std::async 并发编程如此⽅便的原 因。 auto fut = std::async(f); // run f using default launch policy // - ⽆法预测f是否会与t同时运⾏,因为f可能被安排延迟运⾏ // - ⽆法预测f是否会在调⽤ get或wait 的线程上执⾏。如果那个线程是t,含义就是⽆法预测f是否也在 线程t上执⾏ // - ⽆法预测f是否执⾏,因为不能确保 get或者wait 会被调⽤ // 默认启动策略的调度灵活性导致使⽤线程本地变量⽐较⿇烦,因为这意味着如果f读写了线程本地存储 (thread-local storage, TLS),不可能预测到哪个线程的本地变量被访问: auto fut = std::async(f); // TLS for f possibly for independent thread, but possibly for thread invoking get or wait on fut // 还会影响到基于超时机制的wait循环,因为在task的 wait_for 或者 wait_until 调⽤中会产⽣延迟求值(当wait或者get被调用才异步执行函数)( std::launch::deferred )。意味着,以下循环看似应该终⽌,但是实际上永 远运⾏: usingnamespace std::literals; //为了使用C++14中的时间段后缀;参见条款34
// 这种有话讲仅仅在内存表现正常时有效。“特殊”的内存不⾏。最常⻅的“特殊”内存是⽤来mapped I/O的内存。这种内存实际上是与外围设备(⽐如外部传感器或者显⽰器,打印机,⽹络端口) 通信,而不是读写(⽐如RAM)。这种情况下,再次考虑多余的代码: auto y = x; // read x y = x; // read x again // 如果x的值是⼀个温度传感器上报的,第⼆次对于x的读取就不是多余的,因为温度可能在第⼀次和第⼆ 次读取之间变化。类似的,写也是⼀样: x = 10; x = 20; // 如果x与⽆线电发射器的控制端口关联,则代码时控制⽆线电,10和20意味着不同的指令。优化会更改 第⼀条⽆线电指令。 // volatile 是告诉编译器我们正在处理“特殊”内存。意味着告诉编译器“不要对这块内存执⾏任何优化”。 所以如果x对应于特殊内存,应该声明为 volatile : volatileint x; auto y = x; y = x; // can't be optimized away x = 10; // can't be optimized away x = 20; // 在处理特殊内存时,必须保留看似多余的读取或者⽆效存储的事实,顺便说明了为什么 std::atomic 不 适合这种场景。 std::atomic 类型允许编译器消除此类冗余操作。代码的编写⽅式与使⽤ volatile 的 ⽅式完全不同,但是如果我们暂时忽略它,只关注编译器执⾏的操作,则可以说, std::atomic<int> x; auto y = x; //概念上会读x(见下) y = x; //概念上会再次读x(见下) x = 10; //写x x = 20; //再次写x // 原则上,编译器可能会优化为: auto y = x; // conceptually read x x = 20; // write x // 对于特殊内存,显然这是不可接受的
// 因为 std::atomic 和 volatile ⽤于不同的⽬的,所以可以结合起来使⽤: volatile std::atomic<int> vai; // operations on vai are atomic and can't be optimized away // 这可以⽤在⽐如 vai 变量关联了memory-mapped I/O内存并且⽤于并发程序的场景。
// 最后⼀点,⼀些开发者尤其喜欢使⽤ std::atomic 的 load 和 store 函数即使不必要时,因为这在代码 中显式表明了这个变量不“正常”。强调这⼀事实并⾮没有道理。因为访问 std::atomic 确实会更慢⼀ 些,我们也看到了 std::atomic 会阻⽌编译器对代码执⾏顺序重排。调⽤ load 和 store 可以帮助识别 潜在的可扩展性瓶颈。从正确性的⻆度来看,没有看到在⼀个变量上调⽤ store 来与其他线程进⾏通信 (⽐如flag表⽰数据的可⽤性)可能意味着该变量在声明时没有使⽤ std::atomic 。这更多是习惯问 题,但是,⼀定要知道 atomic 和 volatile 的巨⼤不同。


 |
|  |
|