dataStructure_BinaryIndexedTree - 二叉索引树(树状数组)
BITree 详解
1 Binary Indexed Tree(二元索引树)(树状数组)
- 1 用途:以O(log n)时间复杂度得到任意区间和。同时支持在O(log n)时间内支持动态单点值的修改。空间复杂度O(n)。
- 2 出处:Peter M. Fenwick. A new data structure for cumulative frequency tables. Software: Practice and Experience. 1994, 24 (3): 327–336. doi:10.1002/spe.4380240306.
- 3 原理:按照Peter M. Fenwick的说法,正如所有的整数都可以表示成2的幂和,我们也可以把一串序列表示成一系列子序列的和。采用这个想法,我们可将一个前缀和划分成多个子序列的和,而划分的方法与数的2的幂和具有极其相似的方式。一方面,子序列的个数是其二进制表示中1的个数,另一方面,子序列代表的f[i]的个数也是2的幂。
如下说明也很贴切:1
2How does Binary Indexed Tree work?
The idea is based on the fact that all positive integers can be represented as the sum of powers of 2. For example 19 can be represented as 16 + 2 + 1. Every node of the BITree stores the sum of n elements where n is a power of 2. For example, in the first diagram above (the diagram for getSum()), the sum of the first 12 elements can be obtained by the sum of the last 4 elements (from 9 to 12) plus the sum of 8 elements (from 1 to 8). The number of set bits in the binary representation of a number n is O(Logn). Therefore, we traverse at-most O(Logn) nodes in both getSum() and update() operations. The time complexity of the construction is O(nLogn) as it calls update() for all n elements.2 直观解释
- 1 C[i]表示f[1]…f[i]的和,而用tree[idx]表示某些子序列的和
- 2 实际上tree[idx]是那些indexes from (idx - 2^r + 1) to idx的f[index]的和,其中r是idx最右边的那个非零位到右边末尾的0的个数,比如:
- eg 2.0 当idx=8 decimal = 1000,有r=3,则,tree[8] = f[1] + … + f[8],
- eg 2.1 当idx=11 decimal = 1011,有r=0,则,tree[11] = f[11],
- eg 2.2 当idx=12 decimal = 1100,有r=2,则,tree[12] = f[9] + f[10] + f[11] + f[12],
- eg 2.3 当idx=14 decimal = 1110,有r=1,则,tree[14] = f[13] + f[14]
- 3 有了上面tree这个数组(也就是bit本体),我们可以得到: C[13] = tree[13] + tree[12] + tree[8]
- 从上述例子可以得出一个重要结论:求前idx个和,也就是求C[idx]的时候,idx中1的个数即为构成C[idx]的子序列的个数,也就是有多少个tree中的元素加起来
C1 = f1
C2 = f1 + f2
C3 = f3
C4 = f1 + f2 + f3 + f4
C5 = f5
C6 = f5 + f6
C7 = f7
C8 = f1 + f2 + f3 + f4 + f5 + f6 + f7 + f8
…
C16 = f1 + f2 + f3 + f4 + f5 + f6 + f7 + f8 + f9 + f10 + f11 + f12 + f13 + f14 + f15 + f16
- 从上述例子可以得出一个重要结论:求前idx个和,也就是求C[idx]的时候,idx中1的个数即为构成C[idx]的子序列的个数,也就是有多少个tree中的元素加起来
- 4 有了3作为基础,求前缀和过程如下:4,5参考
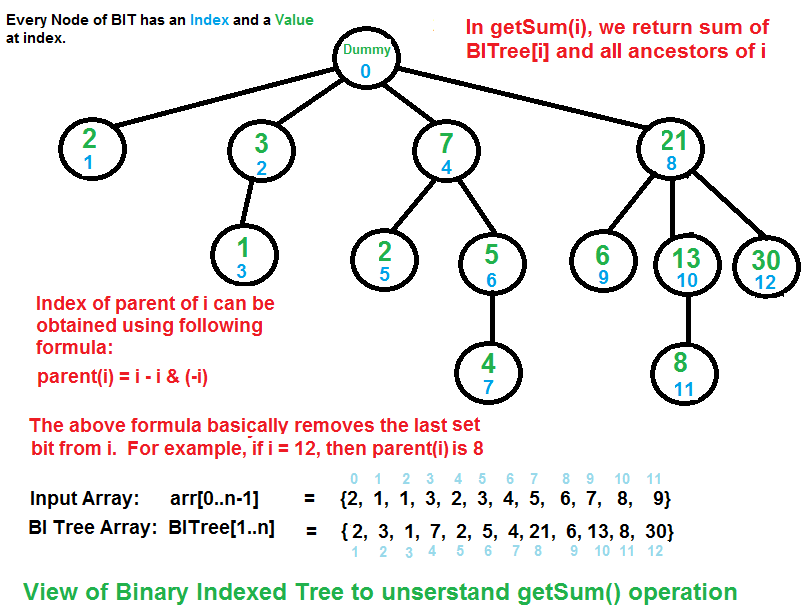
- 4.1 tree[y] 是 tree[x] 的父节点,当且仅当可以通过从 x 的二进制表示中去除最后一个设置位(即数位为1的位)来获得 y,即 y = x – (x & (-x))。
- lowbit函数 就是 取最后一个设置位的函数,lowbit = [](int x) int {return (x & (-x));}
- eg: tree[8]是tree[10]的父节点,因为 10 - (10&(-10)) == 8 为true
- 4.2 节点 tree[y] 的子节点 tree[x] 存储了 y(inclusive) 和 x(exclusive) 之间元素的总和:arr[y,…,x)。
- 4.3 实际例子:求C[11] = C[1011]:
- 4.3.1 看下图即可,很显然我们需要沿着路径一直加到dummy node(tree[0]其值为0,方便运算而已)为止,从这里能够再一次看出,为何其前缀和的算法时间复杂度为O(log n),因为路径上的node个数就是C[1011]中的1的个数
- C[1011] = C[11] = tree[11] + tree[10] + tree[8]
- 4.3.2具体代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15int getSum(int BITree[], int index)
{
int sum = 0; // Initialize result
// index in BITree[] is 1 more than the index in arr[]
index = index + 1;
// Traverse ancestors of BITree[index]
while (index>0)
{
// Add current element of BITree to sum
sum += BITree[index];
// Move index to parent node in getSum View
index -= index & (-index);
}
return sum;
}
- 4.1 tree[y] 是 tree[x] 的父节点,当且仅当可以通过从 x 的二进制表示中去除最后一个设置位(即数位为1的位)来获得 y,即 y = x – (x & (-x))。
- 5 更新BITree
- 5.1 类似4中的求和,更改一个节点需要更改所有被当前节点所影响的子节点
- 5.2 子节点的获取: parent of idx = idx + (idx & (-idx));
- 5.3 举个例子,如4中的图:对于idx = 2这个点,需要更新节点4,8
1
2
3
4
5
6
7
8
9
10
11
12
13void updateBIT(int BITree[], int n, int index, int val)
{
// index in BITree[] is 1 more than the index in arr[]
index = index + 1;
// Traverse all ancestors and add 'val'
while (index <= n)
{
// Add 'val' to current node of BI Tree
BITree[index] += val;
// Update index to that of parent in update View
index += index & (-index);
}
}
3 整体实现
1 | // C++ code to demonstrate operations of Binary Index Tree |
实际例题
剑指 Offer 51. 数组中的逆序对
1 题目
https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/
2 解题思路
- 1 思路:
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- index -> 1 2 3 4 5 6 7 8 9
- value -> 0 1 1 0 2 1 0 0 0
- 1.2 那么上述过程中,比如对于5,其贡献的逆序数对为5之前所有数字出现次数的和,也就是value数组中2之前的前缀和!
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- 2 那么如何快速获得前缀和呢?考虑使用BST来获取,参考:
- 2.1 整体思路如下:
- a 使用数字在数组中的排名来代替数字(这不会对逆序数对的个数产生影响)
- b 对数组nums中的元素nums[i]从右到左构建BITree(i 从 n-1 到 0),注意,BITree所对应的前缀和是数组里数字出现次数的和
- 比如进行到nums[i],那么nums[i]右边的数字都已经统计了他们的出现次数,而后获取nums[i] - 1的前缀和,即可获取所有 < nums[i]的数字在nums[i:n]中的出现次数之和,也就是nums[i]贡献的逆序数对的个数
- 之所以是逆序遍历构建BITree,是因为对于nums[i],它能够贡献的逆序数对的个数仅仅出现在它的右侧,所以需要在右侧进行
- 2.2 额外说一下数组离散化,也就是不关系数字大小本身,只关心他们之间的相对排位相似题目:
1
2
3
4
5sort(sortNoNums.begin(), sortNoNums.end(), std::less<int>());
for(auto& num : nums) {
num = lower_bound(sortNoNums.begin(), sortNoNums.end(), num) - sortNoNums.begin() + 1;
}
https://leetcode-cn.com/problems/count-of-smaller-numbers-after-self/
- 2.1 整体思路如下:
1 | class Solution { |
0315. 计算右侧小于当前元素的个数
1 题目
https://leetcode-cn.com/problems/count-of-smaller-numbers-after-self/
题和逆序数对的计算方式相同:https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/
2 解题思路
- 1 思路:
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- index -> 1 2 3 4 5 6 7 8 9
- value -> 0 1 1 0 2 1 0 0 0
- 1.2 那么上述过程中,比如对于5,其贡献的逆序数对为5之前所有数字出现次数的和,也就是value数组中2之前的前缀和!
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- 2 那么如何快速获得前缀和呢?考虑使用BST来获取,参考:https://xychen5.github.io/2021/12/15/dataStructure-BinaryIndexedTree/
- 2.1 整体思路如下:
- a 使用数字在数组中的排名来代替数字(这不会对逆序数对的个数产生影响)
- b 对数组nums中的元素nums[i]从右到左构建BITree(i 从 n-1 到 0),注意,BITree所对应的前缀和是数组里数字出现次数的和
- 比如进行到nums[i],那么nums[i]右边的数字都已经统计了他们的出现次数,而后获取nums[i] - 1的前缀和,即可获取所有 < nums[i]的数字在nums[i:n]中的出现次数之和,也就是nums[i]贡献的逆序数对的个数
- 之所以是逆序遍历构建BITree,是因为对于nums[i],它能够贡献的逆序数对的个数仅仅出现在它的右侧,所以需要在右侧进行
- 2.2 额外说一下数组离散化,也就是不关系数字大小本身,只关心他们之间的相对排位如下的过程并没有使用离散化,但是空间浪费也不是很多,超过百分之83吧
1
2
3
4
5sort(sortNoNums.begin(), sortNoNums.end(), std::less<int>());
for(auto& num : nums) {
num = lower_bound(sortNoNums.begin(), sortNoNums.end(), num) - sortNoNums.begin() + 1;
}
- 2.1 整体思路如下:
1 | class Solution { |
0327. 区间和的个数
1 题目
https://leetcode-cn.com/problems/count-of-range-sum/
题和逆序数对的计算方式相同:https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/
就是做了一个小改变而已,很多统计区间值的,st-ed < tar, 本来是让你找一个st,ed的对子的,那么就会转换思路为:
对于每一个ed找st,什么样的呢? st < ed + tar
然后找这样的st就有很多方法,比如hash,前缀和,bitree,priority_queue
2 解题思路
- 1 求逆序对的思路:
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- index -> 1 2 3 4 5 6 7 8 9
- value -> 0 1 1 0 2 1 0 0 0
- 1.2 那么上述过程中,比如对于5,其贡献的逆序数对为5之前所有数字出现次数的和,也就是value数组中2之前的前缀和!
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- 2 那么如何快速获得前缀和呢?考虑使用BST来获取,参考:https://xychen5.github.io/2021/12/15/dataStructure-BinaryIndexedTree/
- 2.1 整体思路如下:
- a 使用数字在数组中的排名来代替数字(这不会对逆序数对的个数产生影响)
- b 对数组nums中的元素nums[i]从右到左构建BITree(i 从 n-1 到 0),注意,BITree所对应的前缀和是数组里数字出现次数的和
- 比如进行到nums[i],那么nums[i]右边的数字都已经统计了他们的出现次数,而后获取nums[i] - 1的前缀和,即可获取所有 < nums[i]的数字在nums[i:n]中的出现次数之和,也就是nums[i]贡献的逆序数对的个数
- 之所以是逆序遍历构建BITree,是因为对于nums[i],它能够贡献的逆序数对的个数仅仅出现在它的右侧,所以需要在右侧进行
- 2.2 额外说一下数组离散化,也就是不关系数字大小本身,只关心他们之间的相对排位
- 2.1 整体思路如下:
- 3 那么小改变在哪里呢?
- 就是查一次查不出来了,要查两次做一个差
- 还有一点就是,注意将所有要query和update的值,都用序号表示,这样避免tree过大实现代码如下:
1
2
3for a valid s(i, j) we shall find:
preSum[j] - ub <= preSum[i] <= preSum[j] - lb
we just need to statistic those preSum[i] for each j1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70class Solution {
public:
// when count the num, try to use BItree to count the appeared num, prefixSum to
// get how many < curNum will be fast
class BITree{
public:
int n;
vector<int> tree;
BITree (int _n) : n(_n), tree(_n + 1) {}
int lowBit(int x) {
return x & (-x);
}
int query(int x) {
int sum = 0;
while(x > 0) {
sum += tree[x];
x -= lowBit(x);
}
return sum;
}
void update(int x, int val) {
while(x <= n) {
// cout << "x and tree[x] " << x << "->" << tree[x] << endl;
tree[x] += val;
x += lowBit(x);
}
}
};
int countRangeSum(vector<int>& nums, int lower, int upper) {
unordered_map<int, int> numToIdx;
set<long long> tmpNums;
vector<long long> prefixSum = {0};
for(int i = 0; i < nums.size(); ++i) {
prefixSum.emplace_back(nums[i] + prefixSum.back());
}
for(auto ps : prefixSum) {
tmpNums.insert(ps);
tmpNums.insert(ps - lower);
tmpNums.insert(ps - upper);
}
int i = 1;
for(auto num : tmpNums) {
numToIdx[num] = i++;
}
// for a valid s(i, j) we shall find:
// preSum[j] - ub <= preSum[i] <= preSum[j] - lb
// we just need to statistic those preSum[i] for each j
int n = tmpNums.size();
BITree tree(n + 1);
long long ans = 0;
for(int j = 0; j < prefixSum.size(); ++j) {
int leftBound = numToIdx[prefixSum[j] - upper];
int rightBound = numToIdx[prefixSum[j] - lower];
// cout << "lb, rb = " << leftBound << " " << rightBound << endl;
ans += (tree.query(rightBound) - tree.query(leftBound - 1));
// cout << "ans = " << ans << "preFixSumSize = " << prefixSum.size() << endl;
tree.update(numToIdx[prefixSum[j]], 1); // avoid 0 to produce dead loop
}
return ans;
}
};
3 使用线段树解题
注意其中很重要的一点:
对于线段树中插入一个节点时,需要对沿路所有节点的sum加上要插入的节点的值,找这个节点位置的时候,
需要找到root左右管辖范围的中间值mid,此时务必使用>>1去做,因为获得mid我们要求其为 floor(left + right),
但是:(cpp和python对于移位和除法的逻辑是相同的),这里就显示出了2者的区别,
当然在数字都为正数的时候不会出错!
1 | int((-1 + 0) / 2) |
1 | class Solution { |
0493 翻转对
1 题目
https://leetcode-cn.com/problems/reverse-pairs/
题和逆序数对的计算方式相同:https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/
就是做了一个小改变而已,很多统计区间值的,st-ed < tar, 本来是让你找一个st,ed的对子的,那么就会转换思路为:
对于每一个ed找st,什么样的呢? st < ed + tar
然后找这样的st就有很多方法,比如hash,前缀和,bitree,priority_queue
2 解题思路
- 1 求逆序对的思路:
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- index -> 1 2 3 4 5 6 7 8 9
- value -> 0 1 1 0 2 1 0 0 0
- 1.2 那么上述过程中,比如对于5,其贡献的逆序数对为5之前所有数字出现次数的和,也就是value数组中2之前的前缀和!
- 1.1 首先注意到:对于数组{5,5,2,3,6}而言,得到每个value的个数的统计:
- 2 那么如何快速获得前缀和呢?考虑使用BST来获取,参考:https://xychen5.github.io/2021/12/15/dataStructure-BinaryIndexedTree/
- 2.1 整体思路如下:
- a 使用数字在数组中的排名来代替数字(这不会对逆序数对的个数产生影响)
- b 对数组nums中的元素nums[i]从右到左构建BITree(i 从 n-1 到 0),注意,BITree所对应的前缀和是数组里数字出现次数的和
- 比如进行到nums[i],那么nums[i]右边的数字都已经统计了他们的出现次数,而后获取nums[i] - 1的前缀和,即可获取所有 < nums[i]的数字在nums[i:n]中的出现次数之和,也就是nums[i]贡献的逆序数对的个数
- 之所以是逆序遍历构建BITree,是因为对于nums[i],它能够贡献的逆序数对的个数仅仅出现在它的右侧,所以需要在右侧进行
- 2.2 额外说一下数组离散化,也就是不关系数字大小本身,只关心他们之间的相对排位
- 2.1 整体思路如下:
- 3 那么小改变在哪里呢?
- 对于每个j,找位于它之前的数字,满足:nums[i] > 2*nums[j]
- 找的方法为用总体减去目标的补集:用nums[j]之前所有的数字的个数,减去小于等于nums[j] * 2的数字就行
for each j, find those nums[i]:
which satisty: i < j && nums[i] > 2*nums[j]so, we can get this by: using all to sub those nums[i] <= nums[j] * 2 to get the res
preSum[1 -> 2*n] - preSum[1 -> 2*nums[j]]
实现代码如下:
1 | class Solution { |
